Кодирование
1. Основные понятия
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, - только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Наиболее простой способ кодирования – побуквенный. При побуквенном кодировании каждому символу из исходного алфавита сопоставляется кодовое слово – слово в кодовом алфавите. Иногда вместо «кодовое слово буквы» говорят просто «код буквы». При побуквенном кодировании текста коды всех символов записываются подряд, без разделителей.
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита - 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, - префиксом) другого кодового слова.
Код из примера 1 – НЕ префиксный, так как, например, код буквы А (т.е. кодовое слово 1) – префикс кода буквы К (т.е. кодового слова 12, префикс выделен жирным шрифтом).
Код из примера 2 (и любой другой равномерный код) – префиксный: никакое слово не может быть началом слова той же длины.
Пример 3. Пусть исходный алфавит включает 9 символов: А, Л, М, О, П, Р, У, Ы, -. Кодовый алфавит – двоичный. Кодовые слова:
А: 00 М: 01 -: 100 Л: 101 У: 1100 Ы: 1101 Р: 1110 О: 11110 П: 11111Кодовые слова выписаны в алфавитном порядке. Видно, что ни одно из них не является началом другого. Это можно проиллюстрировать рисунком
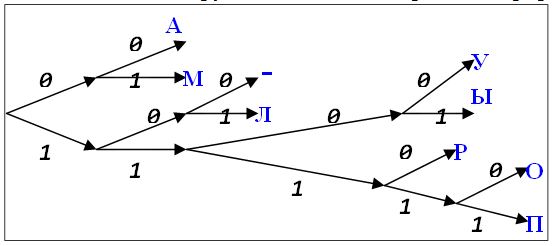 На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
Теорема (условие Фано). Любой префиксный код (а не только равномерный) допускает однозначное декодирование.
Разбор примера (вместо доказательства). Рассмотрим закодированный текст, полученный с помощью кода из примера 3:
0100010010001110110100100111000011100
Будем его декодировать таким способом. Двигаемся слева направо, пока не обнаружим код какой-то буквы. 0 – не кодовое слово, а 01 – код буквы М.
0100010010001110110100100111000011100
Значит, исходный текст начинается с буквы М: код никакой другой буквы не начинается с 01! «Отложим» начальные 01 в сторону и продолжим.
01 00010010001110110100100111000011100 МДалее таким же образом находим следующее кодовое слово 00 – код буквы А.
01 00010010001110110100100111000011100 М АДоведите расшифровку текста до конца самостоятельно. Убедитесь, что он расшифровывается (декодируется) однозначно.
Замечание. В расшифрованном тексте 14 букв. Т.к. в алфавите 9 букв, то при равномерном двоичном кодировании пришлось бы использовать кодовые слова длины 4. Таким образом, при равномерном кодировании закодированный текст имел бы длину 56 символов – в полтора раза больше, чем в нашем примере (у нас 37 символов).
4. Как все это повторять. Задачи на понимание
Знание приведенного выше материала достаточно для решения задачи 5 из демо-варианта и близких к ней (см. здесь). Повторять (учить) этот материал стоит в том порядке, в котором он изложен. При этом нужно решать простые задачи – до тех пор, пока не будет достигнуто полное понимание. Ниже приведены возможные типы таких задач. Опытные учителя легко придумают (или подберут) конкретные задачи таких типов. Если будут вопросы – пишите.
1) Понятие побуквенного кодирования.
Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Закодировать заданный текст в алфавите Ф. Коды могут быть с использованием разных кодовых алфавитов, равномерные и неравномерные.
2) Префиксные неравномерные коды.
2.1) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Построить дерево кода (см. рис.1) и убедиться, что код – префиксный.
2.2) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Декодировать (анализом слева направо) данный текст в кодовом алфавите.
2.3) Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Определить, является ли данный код префиксным, или нет. В качестве примеров полезно приводить:
- Равномерный код. - Неравномерный префиксный код (полезно нарисовать депево этого кода как на рис.1). - Различные пополнения данного неравномерного префиксного кода с помощью кода еще одной буквы так, чтобы полученный код либо оставался префиксным, либо переставал им быть. При анализе дополнительной буквы полезно использовать дерево исходного кода. Полезно рассмотреть различные варианты «потери префиксности»: (а) новый код – начало одного из старых; (б) один из старых кодов – начало нового.2.4) Решать задачи для самостоятельного решения, например, отсюда
17 комментариев
Бухгалтерские записи
Бухгалтерские услуги для ООО https://buhmoy.ru/.
Помогите пожалуйста расшифровать:шцшончочнюыъъзцнбуэ рцщньуэутн пццвулнюрыцщныъонэоючцъ рдцюинъупэуфъыншуфошоняышичынюыънщмяуфъзцнрышъ мнтурюяруъъ лнсэ тинщудошнюрыпытъынуцнрхтыбъ яи
Продам комплект качественные ( профессиональные) горные лыжи 120 см, палки, горнолыжные ботинки LANGE TIME PRO (профессиональные) размер 22.5
помогите расшифровать:
10000100010 10001001011 100000 10000110001
10001001011 10000111011 100000 10000111111
10001000000 10000110000 10000110010
Хм интересно, но что означает цыфра 34 в равномерном буквенном коде.
Пришлите пожалуйста пример, разберёмся!
Спасибо очень помогло!!!
Помогите расшифровать @^$#@
111669'39,53 57' 8 2363' 39 8 92 помогите расшифровать?
Спасибо огромное за статью! Способ с деревом помог мне разобраться с решением множества задач, касающихся условия Фано.
Рады помочь 🙂 Если есть вопросы/пожелания/предложения - пишите.
Удачи!
Хороший файл с примерами. Хоть уже и устаревший, но для понимания самый раз.
Спасибо на добром слове 🙂
А что бы ты посоветовал добавить?
Удачи!
НЕ очень полезно!!!!!
Кому как:)
А что Вы хотели бы увидеть? Посоветуйте - сделаем.
в рисунке мне кажется сделана ошибка.
1110-Р а не О.
Спасибо, исправили. Удачи!